
| (Anterior) Session EJB's (Stateful y Stateless) |
| BMP ("Bean Managed Persistence") (Siguiente) |
|
Ciclo de Ejecución.
El ciclo de ejecución para un Entity EJB aunque similar al de un Session EJB varía en que debe interactuar con un depósito de Información ajeno al Application Server, típicamente una Base de Datos.
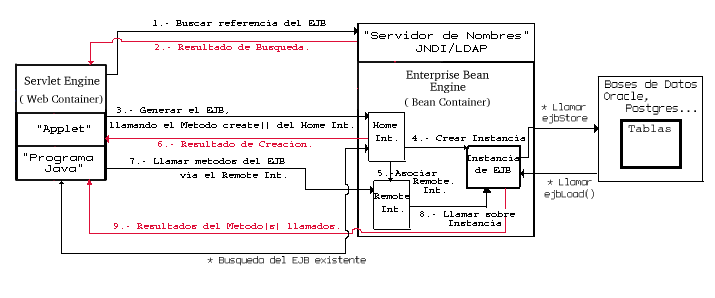 |
Localización y Sincronización .
Localización .
La primer diferencia de un Entity EJB comparado con un Session EJB es el concepto de búsqueda sobre un posible EJB existente, la razón de esto es más clara analizando el funcionamiento de ambos tipos de EJB's.
Al utilizar un Session bean en su modalidad de "Stateless" no existe ningún tipo de estado (como su nombre lo implica) para el cliente que interactúa con el EJB, esto es, la interacción entre ambos no requiere de conocimiento previo, se invoca el EJB y la operación se da por terminada y en dado caso de ser necesario reinvocar el EJB no es de interés las acciones anteriores.
Cuando se interactúa con depósitos de información mediante EJB's , lo citado previamente merece varias consideraciones. Al crearse un EJB para manipular información residente en Bases de Datos se trae una copia de ésta al EJB , dicha información puede variar desde datos personales, cuentas bancarias o cualquier otro tipo que sea conveniente persistir a través del tiempo, es aquí donde se hace más clara la necesidad de localización.
Cuando el cliente (JSP/Servlet) genera un "Entity EJB" éste seguramente volverá hacer uso del EJB, tomando el caso de una cuenta bancaria, el cliente puede invocar una operación sobre la información de "x" cuenta, si posteriormente se deseara invocar otra operación sobre estos datos, no solo sería excesivo volver a extraer la información de la Base de Datos, sino ilógico , puesto que ya están en el Application Server/"EJB Container". La manera en que son re-localizados EJB's ya creados es a través de métodos de búsqueda , denominados finder methods.
Estos finder methods pueden ser de cualquier tipo imaginable ya que son diseñados por el creador del EJB, dependiendo de la información estos pueden ser: findEnRango, findByPrimaryKey, findPorApellido,etc; el vocablo find es utilizado como una convención para distinguir su uso, estos métodos son declarados en el Home Interface del EJB, sin embargo, esto se explorará a fondo en la codificación de un Entity EJB.
Sincronización
La sincronización de información entre el EJB y el depósito de información es otra propiedad de un Entity EJB y su importancia se debe a las características de los datos residentes en Bases de Datos.
Regresando al caso de una cuenta bancaria, si esta información es manipulada a través de un EJB es de suma importancia que sea sincronizada con aquella de la Base de Datos , Porqué ? Suponga que el EJB deduce "x" cantidad de dinero a una cuenta, debido a que es posible que la información residente en una Base de Datos sea manipulada por otro sistema (Otra sistema: Sucursal o Cajero automático), es conveniente sincronizar de inmediato este tipo de operaciones para asegurarse que el juego de datos en el EJB no ha cambiado respecto al depósito central.
Este mismo caso se puede suscitar si después de un lapso extenso de tiempo se desea manipular un "Entity EJB", en este caso, siempre es conveniente re-cargar (sincronizar) la información del EJB con aquella de la Base de Datos para asegurarse que no ha cambiado desde la creación inicial del EJB.
La sincronización de información se lleva acabo a través de dos métodos que deben ser implementados en todo "Entity EJB": ejbLoad y ejbStore; ejbLoad es utilizado para traer información del depósito hacia el EJB y ejbStore es para llevar los datos del EJB hacia la Base de Datos.
Cuando y quien invoca ejbStore y ejbLoad ? , las dos situaciones obvias son al crear y al destruir el "Entity EJB", sin embargo, ambos también pueden ser invocados al llevarse acabo una manipulación crítica como las que fueron mencionadas anteriormente, en este caso el llamar estos métodos es un tema fuertemente relacionado con Transacciones en EJB's. Finalmente cabe mencionar que un cliente (JSP/Servlet) jamás invoca estos métodos directamente, sino que la tarea es delegada al Application Server para ser invocados según se hayan definido las transacciones correspondientes, tema que es descrito en otra sección de este curso.
Tipos de Entity Beans.
Existen dos tipos de "Entity EJB's" denominados "CMP (Container Managed Persistence)" y "BMP (Bean Managed Persistence)" la diferencia entre ambos estriba en la manera en que se accesa la información residente en la Base de Datos.
En "BMP (Bean Managed Persistence)" es necesario escribir toda la lógica de acceso para la Base de Datos, esta lógica escrita a través del API JDBC implica contemplar diversos aspectos de codificación como parámetros, variables, algoritmos, y otros detalles más; si el EJB realiza interacciones complejas con la Base de Datos, este código no solo puede ser complejo de escribir sino difícil de mantener actualizado.
En "CMP (Bean Managed Persistence)" la lógica de acceso hacia la Base de Datos es generada por el Application Server/"EJB Container", si bien suena como una maravilla, este mecanismo tiene sus desventajas comparado con un "BMP". El primer aspecto que es la ventaja de generar código automático es balanceado por la necesidad de contemplar y conocer a detalle configuraciones del Application Server requeridas para emplear "CMP"; la otra desventaja es que como el código es generado automáticamente no existe la posibilidad de afinarlo, el que sea generado código JDBC no implica que ha sido utilizado el mejor algoritmo para el trabajo.
Mapeo Objeto/Relacional.
Una consideración muy importante y en ocasiones no contemplada lo suficiente en desarrollos de "Entity EJB's", es la discrepancia que existe del mundo Java (Objetos) al mundo de Base de Datos (Relacional).
En Java la información es manipulada a través de Objetos, entidades que describen las características y el comportamiento de determinada fuente, sean personas, productos, cuentas bancarias u otro ente; en el mundo de Bases de Datos (Relacionales) empleadas desde hace décadas en distintas industrias para guardar información, los datos no residen en objetos sino en Tablas conformadas por Columnas y Renglones, el entrar en detalle porque se ha venido utilizando el modelo relacional seria tema de diversas horas, el caso es que hoy en día se hace amplio uso de objetos (Java) los cuales deben interactuar directamente con depósitos relacionales(SQL).
El problema que surge al interactuar Objetos (Java) con Bases de Datos (Relacionales) es que no existe un mapeo directo entre ambos, esto es, es posible que un Objeto compuesto por diversos valores requiera interactuar con dos o tres tablas relacionales para lograr el comportamiento deseado; esta discrepancia entre el mundo de Objetos (Java) y el relacional(SQL) es conocida como Impedance Mismatch
Para proyectos pequeños de EJB's este mapeo es realizado directamente por un programador, sin embargo, para proyectos de gran tamaño esto puede resultar incosteable e ineficiente.Hoy día ya existen varios productos que realizan este mapeo rápidamente y eficientemente además de ofrecer otras funcionalidades como "Cache's", "Pooling" hacia la Base de Datos y otros mecanismos más; en si actúan como una capa adicional entre el Application Server/"EJB Container" y la Base de Datos, algunos productos son:
- CocoBase ( http://www.thoughtinc.com ) de Thought Inc.
- Hibernate ( http://www.hibernate.org/ ) un proyecto basado en Software libre -- igual que JBoss.